新SOTA模型的一致性神话
Nano Banana (gemini 2.5 flash image)以其编辑图片的顶尖一致性闻名,排名出来后空降榜一,击败第二名14%。
但你抄来的提示词很可能并不好用。
全网首个3日破千图的创作者,分享3个不为人知的秘密,让你真正掌握这个顶级模型。
7次重试法则
核心发现
我用同样的图片和提示词,重复474次,共消耗了7小时 成功生成了119个图片。
这个实验揭示了Nano Banana的一个重要特征: 相同条件下也会产生5-6种主要分型,每种分型都有显著的内部一致性。(其中有一种可能跟来自LMArena的内部缺陷)
实验原始参考图
本实验基于以下两个原始参考图片进行生成测试,验证Nano Banana的一致性表现

原始参考图1
慕沛灵基础造型参考

原始参考图2
风格迁移目标参考
实验验证案例
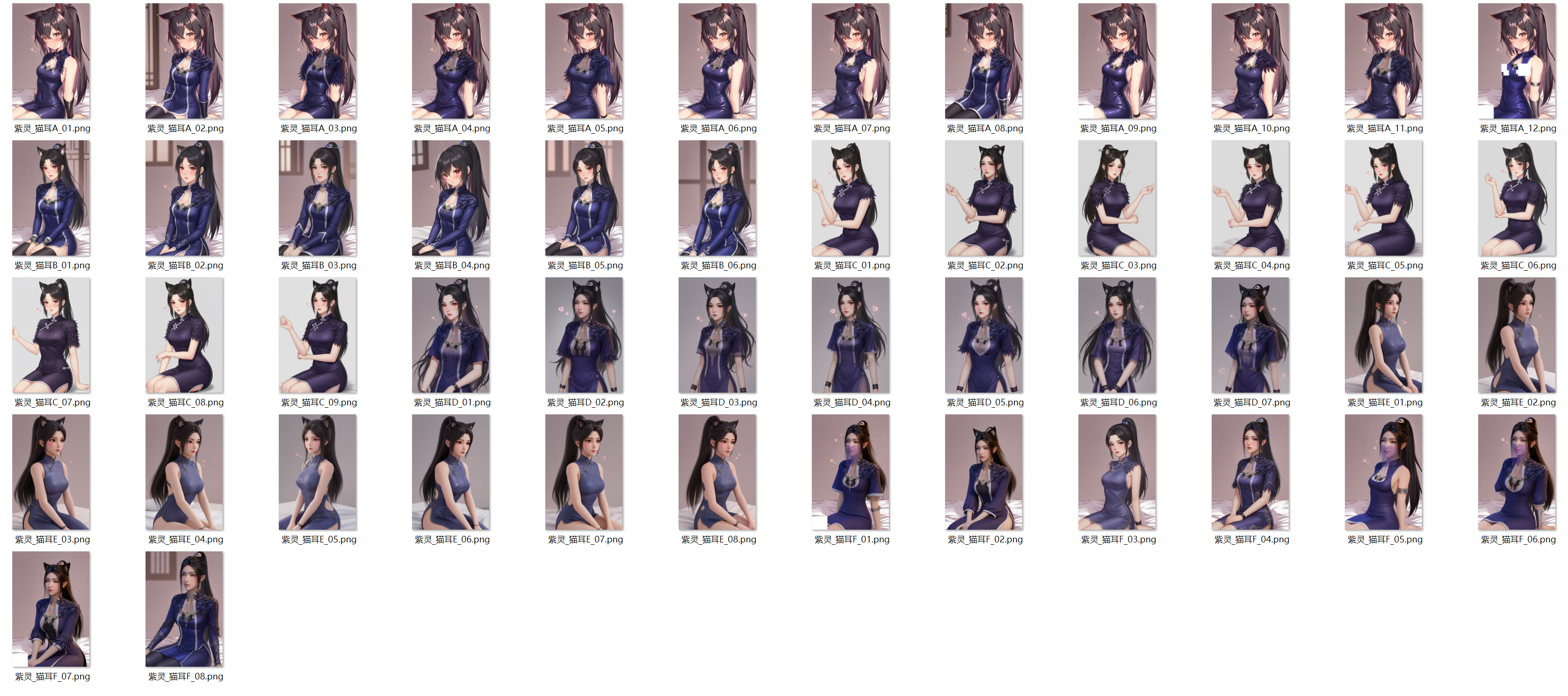
慕沛灵119个成品实验结果


慕沛灵造型A
显著识别出慕沛灵,画风一致的经典造型

慕沛灵造型B
慕沛灵的另一种画风表现

皮克斯风格
与慕沛灵相似度较低,类似皮克斯的角色画风

相似风格
与紧身衣美女相似,但画风偏向皮克斯

原始素材
识别出原始素材紧身衣美女,画风未迁移

生成错误
明显的生成错误,如三只手等
慕沛灵119个成品全景缩略图
119个成品全景缩略图(按6大类分组)- 800×1200分辨率完整显示
分型预览切换器
慕沛灵造型A
显著识别出慕沛灵,画风一致的经典造型
慕沛灵造型B
慕沛灵的另一种画风表现
皮克斯风格
与慕沛灵相似度较低,类似皮克斯的角色画风
相似风格
与紧身衣美女相似,但画风偏向皮克斯
原始素材
识别出原始素材紧身衣美女,画风未迁移
生成错误
明显的生成错误,如三只手等
119个成品分布分析
实验中使用的完整提示词
你将基于两张输入图像(Image A和Image B)生成一张新图像。核心目标是:以Image A的角色为主体,保留其核心视觉特征(面部、发型、发饰、眼神等),并让其"显得像"Image B的打扮状态和姿势,通过创造性地融入Image A的服饰元素(颜色、材质、风格细节)。允许在细节上适当发挥,增加新鲜感,但不得改变Image A的角色身份。遵循以下步骤,每个步骤都必须输出内容供我审阅:
步骤 1:描述输入图像
简要描述Image A和Image B,包含:
角色特征:面部、发型、发饰、眼睛颜色、性别、种族等。
服饰:款式、颜色、材质、纹理、配饰。
姿态与构图:身体姿势、面部朝向、镜头范围(全身/半身)。
背景与艺术风格:现实、动漫、奇幻等。
如果信息不足,注明假设(如"未明确发色,推测为自然色")。
步骤 2:融合规则
角色主体:
新图像的主体必须是Image A的角色,保留其核心特征:
面部特征(脸型、皮肤、鼻子、嘴巴等)。
发型(形状、颜色、长度)、发饰、眼神(颜色、表情)。
其他身份标志(如性别、种族、年龄)。
不得直接使用Image B的角色特征(如发色、眼睛颜色、耳朵形状),除非明确要求。
姿态与构图:
采用Image B的身体姿势、面部朝向和构图,应用到Image A的角色上。
如果风格差异导致不协调(如现实角色配动漫姿态),适当调整姿态细节,使其自然融入Image A的风格。
服饰设计:
款式:使用Image B的服饰款式和结构(如连体衣、裙子、盔甲)。
风格元素:基于Image A的服饰颜色、材质、纹理或标志性细节(如飘逸袖子、特定配饰),创造性地融入Image B的款式。
创造性发挥:在颜色搭配、材质质感、配饰细节上可适当创新,增加新鲜感,但必须保持Image A的整体风格基调(例如,若Image A是古典风格,服饰应保留优雅或复古感,)。
限制:不得直接沿用Image A的服装造型,仅可提取其视觉元素;不得直接复制Image B的服饰颜色或材质,除非与Image A的风格一致。
背景与风格:
默认使用Image A的背景或推测与其风格一致的背景。
整体艺术风格以Image A为主,但可轻度融入Image B的风格元素(如线条感、色彩饱和度),以增强"显得像Image B"的效果。
不得完全采用Image B的风格(如动漫化Image A角色),除非明确要求。
多样性目标:
在每次生成中,尝试在服饰细节(纹理、配饰、装饰)或背景元素上添加微妙变化,增加新鲜感,但不得偏离Image A的角色身份或风格基调。
步骤 3:验证理解
在生成前,简要总结你的融合计划,格式如下:
"主体:Image A的[角色特征],如'深色头发女性、古典面容'。""
"姿态:Image B的[姿势],如'站立、双手下垂'。""
"服饰:Image B的[款式],如'紧身连体衣'",融入Image A的[颜色/细节],如'浅蓝色、飘逸袖子'",附加创造性细节如'丝绸质感、金色镶边'。""
"背景与风格:以Image A的[风格],如'现实主义'"为主,背景为'古典庭院'"。"
如果有不明确的地方,说明假设并等待确认。
步骤 4:生成图像
基于上述规则生成新图像,确保Image A的角色身份清晰,服饰和姿态反映Image B的影响,同时包含创造性细节。
如果用户反馈结果错误(如"主体应是Image A"),重新检查步骤2,优先确保Image A的角色特征完整。
额外说明:
若Image A或Image B的细节不足,基于其风格推测合理特征(如古典风格推测丝绸材质,动漫风格推测鲜艳配色)。
在对话中若用户指出误解,立即调整生成,优先强化Image A的主体身份。第二个验证案例:紫灵和猫娘装扮迁移
可以看出这个分型规律是普遍存在的,且比例也比较接近,推测要么是内部系统提示词有MOE架构,要么是有提示词随机的wildcard
LM Arena双图法
核心技巧:模型筛选
快速抽到Nano Banana的秘密!只有3个模型支持多图编辑:
分辨率差异识别
提供非方型原始参考图(如3:4分辨率)时:
通过分辨率快速识别是否抽中目标模型
高级技巧
单图编辑技巧
提交多图后只需单独声明处理一个图片即可
遮挡推理还原
用白色色块遮挡,让模型推理还原完整图片
技巧演示案例
顺带赠送两个小技巧

模型的强大推理能力可以一定程度弥补缺失的内容
在LMarena生成图片时可能会把对话上下文生成的图片标记在错误的模型里,所以如果没特别的需求,使用时避免上下文可以减少干扰
Gemini上的Meta Prompt
核心优势:上下文迭代优化
LM Arena的限制
- 虽然采用上下文对话,可以补充调试,但不会回复生成的文本
- 无法获取深度优化后的提示词
Gemini的优势
- 支持上下文追问反思
- 逐步迭代优化提示词
我的Meta Prompt使用示例

在Gemini中通过上下文对话迭代优化提示词的实际操作示例
两个提示词优化示例
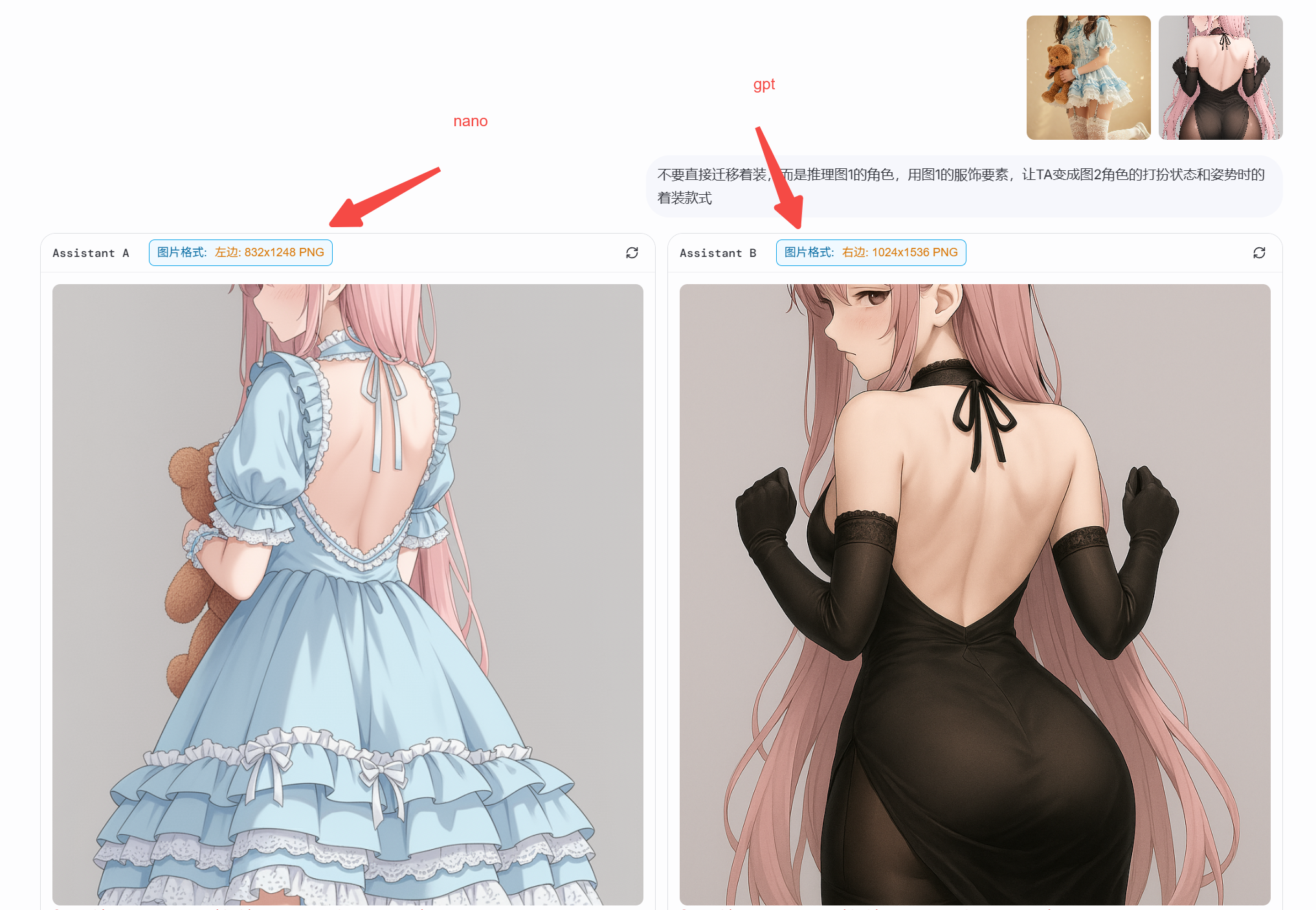
示例一:图像融合技术
最早版本(开放性足够,但依从性差)
不要直接迁移着装,而是推理图1的角色,用图1的服饰要素,让TA变成图2角色的打扮状态和姿势时的着装款式
中间迭代版本(限制严格,多样性差,融合效果生硬)
请基于我提供的Image 1和Image 2生成一张图片,严格遵循以下融合规则:
核心角色:完全继承Image 1中女性角色的面部特征、发型、发饰和眼神细节。
姿势与构图:身体姿势、面部朝向和构图严格参照Image 2。
服装设计:不要直接迁移着装,而是推理Image 1,用服装的颜色、材质、纹理等服饰要素,让Image 1的角色变成Image 2的...
最终版完整提示词
推荐在aistudio中使用,其中步骤3输出的结果也可另行手动修改并独立使用
你将基于两张输入图像(图片1和图片2)生成一张新图像,其中图片1为古风角色,图片2为一个坐在沙发上的角色。
核心目标:以图片1的角色为主体,保留其核心视觉特征(面部、发型、发饰、眼神等),并通过推理图片1的角色身份和服饰要素,使其“显得像”图片2的打扮状态和姿势——不直接迁移着装,而是将图片1的服饰元素(颜色、材质、风格细节)创造性地融合到图片2的款式中。允许在细节上适当发挥以增加新鲜感,但不得改变图片1的角色身份(尤其是面部特征)或图片2的服饰款式类型。
遵循以下步骤一次性完成整个任务,每一步需输出文本供我检查:
步骤 1:描述输入图像
简要描述图片1和图片2,包括:
高区分度的角色特征细节:发饰、眼睛颜色、表情等(不要试图描述角色外观,这会限制你直接依赖图片还原角色特征)
服饰:款式、颜色、材质、纹理、配饰、鞋子、袜子等角色身上穿戴的所有物品。
姿态与构图:身体姿势、面部朝向、镜头范围(全身/半身)。
背景与艺术风格:现实、动漫、奇幻等。
两个图像的描述除上述内容外,还需侧重:
图片1:更丰富的角色配色信息,如角色色板,捕捉所有颜色变化。
图片2:更详尽的服装款式信息,概述款式难以还原精妙之处,需极尽详细。
步骤 2:融合规则
角色主体:
新图像主体必须为图片1的角色,保留核心特征:
发型(形状、颜色、长度)、发饰、眼神(颜色、表情)。
除非明确要求,不得使用图片2的角色特征(如发色、眼睛颜色)。
姿态与构图:
核心:采用图片2的身体姿势和面部朝向。基于图片1角色的气质和服饰风格,创造性演绎肢体细节(例如柔和化或增强表现力),确保自然流畅。构图和镜头范围严格依图片2。
服饰设计:
款式:严格使用图片2的服饰款式和结构(例如连体衣、裙子),包括鞋子和其他配饰。
风格融合:从图片1服饰中抽象提取核心元素,推理图片1角色在图片2打扮状态下的着装:
色彩基调:优先图片1主色调,创造性融入辅色,形成2-3种和谐方案(例如渐变或对比)。
材质质感:借鉴图片1材质特性(如丝绸垂坠感),保留图片2的透明/裸露区域,应用于图片2款式,生成变异(如增加光泽或纹理层)。
标志性细节:将图片1独特设计(袖边、纹样等)转化为图片2上的装饰,允许1-2个新鲜变体(如随机配饰或图案)。
目标:最终服饰为全新设计,继承图片2款式,呼应图片1美学。
限制:不得直接沿用图片1服装造型,仅提取视觉元素;不得复制图片2服饰颜色或材质,除非与图片1风格一致。
背景与风格:
默认:使用图片1背景或推测一致的变体(允许轻度融入图片2元素,如动态光影)。艺术风格以图片1为主,融入图片2微妙元素(如饱和度调整),增强“显得如图片2”效果,不完全采用图片2风格。
作为大师人物摄影,优化光照避免面部暗部,使用柔和光影和高细节渲染(如虚幻引擎5质量),保持一致动漫比例(非大头风格)。
多样性注入:
为提升新鲜感,在服饰细节(纹理、配饰)、姿势微调或背景元素上添加1-3个变异选项(例如“增加金色镶边;略改图案”)。用户可指定变异程度(低/中/高),默认低程度,确保每次生成有微妙差异但不偏离规则。
多样性的低程度示例(如果图片2有丝袜):丝袜的款式和纹理,是否有吊带等。
步骤 3:验证理解
在生成前,总结融合计划。区分示例思考逻辑和正式格式化输出。正式输出使用以下格式化方案,去掉图片1/图片2提及,详细描述融合后设计(尤其是服饰款式和配色),因最终仅提供图片1(对应图片1):
思考逻辑:
角色特征:图片1的[特征]
姿势:图片2的[姿势]
服饰:图片2的[款式],融合图片1的[颜色/细节]
特殊细节:纹身等[细节描述]。
风格:以图片1的[风格],如‘虚幻引擎5古典3D动漫’,背景为‘中式室内传统元素’。
多样性:注入[变异描述]
格式化输出方案(措辞可优化衔接):
基于参考图像创建一个新图像,主体是一个女性角色。
角色特征(基于图片1):
严格基于图片1的角色面部特征和角色画风,[列出其他特征]
姿势(基于图片2):
[列出详细姿势]
服饰(基于图片1配色,图片2款式)
[列出服饰款式和配色细节]
IMPORTANT:[关键强调]
特殊细节:
[列出细节]
风格:
[列出风格],如‘虚幻引擎5质量的古典3D动漫风格’
多样性:
[列出变异]
额外说明:仅使用图片1的女性角色;移除图像中所有文字。
步骤 4:生成图像
基于上述规则生成新图像,确保图片1角色身份清晰,服饰/姿势反映图片2影响,包含创造性细节和多样性变异。
额外说明:
移除图像中所有文字。
示例二:手办生成优化
早期版本问题
- 半身等比例效果非常差
- 角色比例非常丑陋
优化后效果
- 角色比例得到显著改善
- 整体效果提升明显
原始提示词
turn this photo into a character figure. Behind it, place a box with the character's image printed on it, and a computer showing the Blender modeling process on its screen. In front of the box, add a round plastic base with the character figure standing on it. Make the PVC material look clear, and set the scene indoors if possible.
优化后提示词(添加8头身比限制)
Create an indoor scene featuring a high-quality 3D PVC character figure based on a provided photo. The figure is a full-body, anime-style model with a 8-head-to-body ratio, standing in a same dynamic yet elegant pose. with intricate details reflecting the character's outfit and features from the photo. The figure stands on a round plastic base with a subtle design, The base is crafted from clear, glossy PVC material.
优化关键:通过Gemini上下文对话发现缺少头身比限制的问题,针对性加入"8-head-to-body ratio"约束,角色比例得到显著改善。
优化效果对比
手办生成优化前

比例问题明显
手办生成优化后
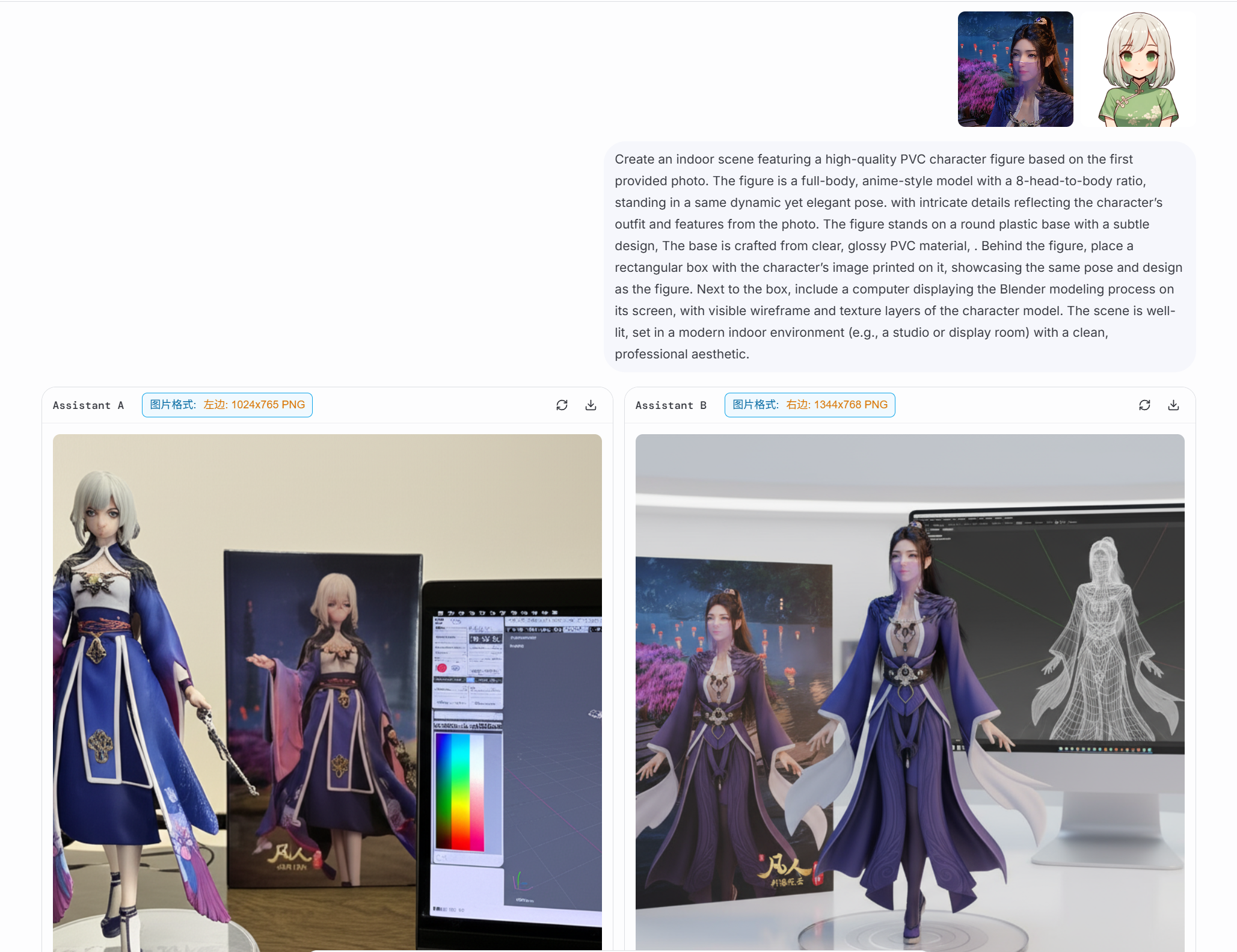
比例显著改善,这里也是一个单图编辑技巧示例
Nano Banana作品集

#宋玉1

#宋玉2

#梅凝1

#梅凝2

#梅凝3

#梅凝4

#紫灵1

#紫灵2

#紫灵3

#紫灵4

#慕沛灵2

#慕沛灵3

#慕沛灵4

#慕沛灵-新常服

#柳玉

#手办1

#手办2

#手办3

#米法手办

#这很简单
所有作品均使用经过Meta Prompt优化的提示词生成,展示了Nano Banana的强大创作能力